Deep Neural Networks with Word-Embedding
Wrapper for Neural Networks for Word-Embedding Vectors
In this package, there is a class that serves a wrapper for various neural network algorithms
for supervised short text categorization:
shorttext.classifiers.VarNNEmbeddedVecClassifier.
Each class label has a few short sentences, where each token is converted
to an embedded vector, given by a pre-trained word-embedding model (e.g., Google Word2Vec model).
The sentences are represented by a matrix, or rank-2 array.
The type of neural network has to be passed when training, and it has to be of
type keras.models.Sequential. The number of outputs of the models has to match
the number of class labels in the training data.
To perform prediction, the input short sentences is converted to a unit vector
in the same way. The score is calculated according to the trained neural network model.
Some of the neural networks can be found within the module :module:`shorttext.classifiers.embed.nnlib.frameworks` and they are good for short text or document classification. Of course, users can supply their own neural networks, written in keras.
A pre-trained Google Word2Vec model can be downloaded here, and a pre-trained Facebook FastText model can be downloaded here.
See: Word Embedding Models .
Import the package:
>>> import shorttext
To load the Word2Vec model,
>>> wvmodel = shorttext.utils.load_word2vec_model('/path/to/GoogleNews-vectors-negative300.bin.gz')
Then load the training data
>>> trainclassdict = shorttext.data.subjectkeywords()
Then we choose a neural network. We choose ConvNet:
>>> kmodel = shorttext.classifiers.frameworks.CNNWordEmbed(len(trainclassdict.keys()), vecsize=300)
Initialize the classifier:
>>> classifier = shorttext.classifiers.VarNNEmbeddedVecClassifier(wvmodel)
- class shorttext.classifiers.embed.nnlib.VarNNEmbedVecClassification.VarNNEmbeddedVecClassifier(wvmodel: gensim.models.keyedvectors.KeyedVectors, vecsize: int | None = None, maxlen: int = 15, with_gensim: bool = False)[source]
Bases:
AbstractScorer,CompactIOMachineNeural network classifier for short text categorization.
Wraps Keras neural network models for supervised short text classification. Each token is converted to an embedded vector using a pre-trained word-embedding model (e.g., Word2Vec). Sentences are represented as matrices (rank-2 or rank-3 arrays) and processed by the neural network.
The neural network model must be a Keras Sequential model with output dimension matching the number of class labels.
- Reference:
Pre-trained Word2Vec: https://code.google.com/archive/p/word2vec/ Example models available in the frameworks module.
- __init__(wvmodel: gensim.models.keyedvectors.KeyedVectors, vecsize: int | None = None, maxlen: int = 15, with_gensim: bool = False)[source]
Initialize the classifier.
- Args:
wvmodel: Word embedding model (e.g., Word2Vec). vecsize: Vector size. Default: None (extracted from model). maxlen: Maximum number of words per sentence. Default: 15. with_gensim: Whether to use gensim format. Default: False.
- convert_trainingdata_matrix(classdict: dict[str, list[str]]) tuple[list[str], Annotated[ndarray[tuple[Any, ...], dtype[float64]], '3D Array'], Annotated[ndarray[tuple[Any, ...], dtype[int64]], '2D Array']][source]
Convert training data to neural network input format.
- Args:
classdict: Training data with class labels as keys and texts as values.
- Returns:
Tuple of (class_labels, embedded_vectors, labels_array).
- train(classdict: dict[str, list[str]], kerasmodel: tensorflow.keras.models.Model, nb_epoch: int = 10)[source]
Train the classifier.
- Args:
classdict: Training data. kerasmodel: Keras Sequential model. nb_epoch: Number of training epochs. Default: 10.
- Raises:
ModelNotTrainedException: If model not loaded.
- savemodel(nameprefix: str) None[source]
Save the trained model to files.
- Args:
nameprefix: Prefix for output files.
- Raises:
ModelNotTrainedException: If not trained.
- loadmodel(nameprefix: str) None[source]
Load a trained model from files.
- Args:
nameprefix: Prefix for input files.
- word_to_embedvec(word: str) ndarray[tuple[Any, ...], dtype[float64]][source]
Convert a word to its embedding vector.
- Args:
word: Input word.
- Returns:
Embedding vector. Returns zeros if word not in vocabulary.
- shorttext_to_matrix(shorttext: str) Annotated[ndarray[tuple[Any, ...], dtype[float64]], '2D Array'][source]
Convert short text to embedding matrix.
- Args:
shorttext: Input text.
- Returns:
Matrix of shape (maxlen, vecsize) with embedding vectors.
- score(shorttext: str, model_params: dict[str, Any] | None = None) dict[str, float][source]
Calculate classification scores for all class labels.
- Args:
shorttext: Input text. model_params: Additional parameters for model prediction.
- Returns:
Dictionary mapping class labels to scores.
- Raises:
ModelNotTrainedException: If not trained.
- classmethod from_pretrained(wvmodel: gensim.models.keyedvectors.KeyedVectors, name: str, compact: bool = True, vecsize: int | None = None) Self[source]
Load a VarNNEmbeddedVecClassifier from file.
- Args:
wvmodel: Word embedding model. name: Model name (compact) or file prefix (non-compact). compact: Whether to load compact model. Default: True. vecsize: Vector size. Default: None.
- Returns:
VarNNEmbeddedVecClassifier instance.
Then train the classifier:
>>> classifier.train(trainclassdict, kmodel)
Epoch 1/10
45/45 [==============================] - 0s - loss: 1.0578
Epoch 2/10
45/45 [==============================] - 0s - loss: 0.5536
Epoch 3/10
45/45 [==============================] - 0s - loss: 0.3437
Epoch 4/10
45/45 [==============================] - 0s - loss: 0.2282
Epoch 5/10
45/45 [==============================] - 0s - loss: 0.1658
Epoch 6/10
45/45 [==============================] - 0s - loss: 0.1273
Epoch 7/10
45/45 [==============================] - 0s - loss: 0.1052
Epoch 8/10
45/45 [==============================] - 0s - loss: 0.0961
Epoch 9/10
45/45 [==============================] - 0s - loss: 0.0839
Epoch 10/10
45/45 [==============================] - 0s - loss: 0.0743
Then the model is ready for classification, like:
>>> classifier.score('artificial intelligence')
{'mathematics': 0.57749695, 'physics': 0.33749574, 'theology': 0.085007325}
The trained model can be saved:
>>> classifier.save_compact_model('/path/to/nnlibvec_convnet_subdata.bin')
To load it, enter:
>>> classifier2 = shorttext.classifiers.VarNNEmbeddedVecClassifier.from_pretrained(wvmodel, '/path/to/nnlibvec_convnet_subdata.bin')
- class shorttext.classifiers.embed.nnlib.VarNNEmbedVecClassification.VarNNEmbeddedVecClassifier(wvmodel: gensim.models.keyedvectors.KeyedVectors, vecsize: int | None = None, maxlen: int = 15, with_gensim: bool = False)[source]
Bases:
AbstractScorer,CompactIOMachineNeural network classifier for short text categorization.
Wraps Keras neural network models for supervised short text classification. Each token is converted to an embedded vector using a pre-trained word-embedding model (e.g., Word2Vec). Sentences are represented as matrices (rank-2 or rank-3 arrays) and processed by the neural network.
The neural network model must be a Keras Sequential model with output dimension matching the number of class labels.
- Reference:
Pre-trained Word2Vec: https://code.google.com/archive/p/word2vec/ Example models available in the frameworks module.
- __init__(wvmodel: gensim.models.keyedvectors.KeyedVectors, vecsize: int | None = None, maxlen: int = 15, with_gensim: bool = False)[source]
Initialize the classifier.
- Args:
wvmodel: Word embedding model (e.g., Word2Vec). vecsize: Vector size. Default: None (extracted from model). maxlen: Maximum number of words per sentence. Default: 15. with_gensim: Whether to use gensim format. Default: False.
- convert_trainingdata_matrix(classdict: dict[str, list[str]]) tuple[list[str], Annotated[ndarray[tuple[Any, ...], dtype[float64]], '3D Array'], Annotated[ndarray[tuple[Any, ...], dtype[int64]], '2D Array']][source]
Convert training data to neural network input format.
- Args:
classdict: Training data with class labels as keys and texts as values.
- Returns:
Tuple of (class_labels, embedded_vectors, labels_array).
- train(classdict: dict[str, list[str]], kerasmodel: tensorflow.keras.models.Model, nb_epoch: int = 10)[source]
Train the classifier.
- Args:
classdict: Training data. kerasmodel: Keras Sequential model. nb_epoch: Number of training epochs. Default: 10.
- Raises:
ModelNotTrainedException: If model not loaded.
- savemodel(nameprefix: str) None[source]
Save the trained model to files.
- Args:
nameprefix: Prefix for output files.
- Raises:
ModelNotTrainedException: If not trained.
- loadmodel(nameprefix: str) None[source]
Load a trained model from files.
- Args:
nameprefix: Prefix for input files.
- word_to_embedvec(word: str) ndarray[tuple[Any, ...], dtype[float64]][source]
Convert a word to its embedding vector.
- Args:
word: Input word.
- Returns:
Embedding vector. Returns zeros if word not in vocabulary.
- shorttext_to_matrix(shorttext: str) Annotated[ndarray[tuple[Any, ...], dtype[float64]], '2D Array'][source]
Convert short text to embedding matrix.
- Args:
shorttext: Input text.
- Returns:
Matrix of shape (maxlen, vecsize) with embedding vectors.
- score(shorttext: str, model_params: dict[str, Any] | None = None) dict[str, float][source]
Calculate classification scores for all class labels.
- Args:
shorttext: Input text. model_params: Additional parameters for model prediction.
- Returns:
Dictionary mapping class labels to scores.
- Raises:
ModelNotTrainedException: If not trained.
- classmethod from_pretrained(wvmodel: gensim.models.keyedvectors.KeyedVectors, name: str, compact: bool = True, vecsize: int | None = None) Self[source]
Load a VarNNEmbeddedVecClassifier from file.
- Args:
wvmodel: Word embedding model. name: Model name (compact) or file prefix (non-compact). compact: Whether to load compact model. Default: True. vecsize: Vector size. Default: None.
- Returns:
VarNNEmbeddedVecClassifier instance.
- shorttext.classifiers.embed.nnlib.VarNNEmbedVecClassification.load_varnnlibvec_classifier(wvmodel: gensim.models.keyedvectors.KeyedVectors, name: str, compact: bool = True, vecsize: int | None = None) VarNNEmbeddedVecClassifier[source]
Deprecated. Use ~VarNNEmbeddedVecClassifier.from_pretrained.
Provided Neural Networks
There are three neural networks available in this package for the use in
shorttext.classifiers.VarNNEmbeddedVecClassifier,
and they are available in the module shorttext.classifiers.frameworks.
- shorttext.classifiers.embed.nnlib.frameworks.CNNWordEmbed(nb_labels: int, wvmodel: gensim.models.keyedvectors.KeyedVectors | None = None, nb_filters: int = 1200, n_gram: int = 2, maxlen: int = 15, vecsize: int = 300, cnn_dropout: float = 0.0, final_activation: Literal['softplus', 'softsign', 'relu', 'tanh', 'sigmoid', 'hard_sigmoid', 'linear'] = 'softmax', dense_wl2reg: float = 0.0, dense_bl2reg: float = 0.0, optimizer: Literal['sgd', 'rmsprop', 'adagrad', 'adadelta', 'adam', 'adamax', 'nadam'] = 'adam') tensorflow.keras.models.Model[source]
Create a CNN for word embeddings.
- Args:
nb_labels: Number of class labels. wvmodel: Word embedding model. If provided, vecsize is extracted from it. nb_filters: Number of filters. Default: 1200. n_gram: N-gram (window size). Default: 2. maxlen: Maximum sentence length. Default: 15. vecsize: Embedding vector size. Default: 300. cnn_dropout: CNN dropout rate. Default: 0.0. final_activation: Final layer activation. Default: softmax. dense_wl2reg: L2 regularization for weights. Default: 0.0. dense_bl2reg: L2 regularization for bias. Default: 0.0. optimizer: Optimizer. Default: adam.
- Returns:
Keras Sequential model.
- Reference:
Yoon Kim, “Convolutional Neural Networks for Sentence Classification,” EMNLP 2014 (arXiv:1408.5882). https://arxiv.org/abs/1408.5882
- shorttext.classifiers.embed.nnlib.frameworks.DoubleCNNWordEmbed(nb_labels: int, wvmodel: gensim.models.keyedvectors.KeyedVectors | None = None, nb_filters_1: int = 1200, nb_filters_2: int = 600, n_gram: int = 2, filter_length_2: int = 10, maxlen: int = 15, vecsize: int = 300, cnn_dropout_1: float = 0.0, cnn_dropout_2: float = 0.0, final_activation: Literal['softplus', 'softsign', 'relu', 'tanh', 'sigmoid', 'hard_sigmoid', 'linear'] = 'softmax', dense_wl2reg: float = 0.0, dense_bl2reg: float = 0.0, optimizer: Literal['sgd', 'rmsprop', 'adagrad', 'adadelta', 'adam', 'adamax', 'nadam'] = 'adam') tensorflow.keras.models.Model[source]
Create a double-layer CNN for word embeddings.
- Args:
nb_labels: Number of class labels. wvmodel: Word embedding model. If provided, vecsize is extracted from it. nb_filters_1: Filters for first layer. Default: 1200. nb_filters_2: Filters for second layer. Default: 600. n_gram: N-gram for first layer. Default: 2. filter_length_2: Window size for second layer. Default: 10. maxlen: Maximum sentence length. Default: 15. vecsize: Embedding vector size. Default: 300. cnn_dropout_1: Dropout for first layer. Default: 0.0. cnn_dropout_2: Dropout for second layer. Default: 0.0. final_activation: Final layer activation. Default: softmax. dense_wl2reg: L2 regularization for weights. Default: 0.0. dense_bl2reg: L2 regularization for bias. Default: 0.0. optimizer: Optimizer. Default: adam.
- Returns:
Keras Sequential model.
- shorttext.classifiers.embed.nnlib.frameworks.CLSTMWordEmbed(nb_labels: int, wvmodel: gensim.models.keyedvectors.KeyedVectors | None = None, nb_filters: int = 1200, n_gram: int = 2, maxlen: int = 15, vecsize: int = 300, cnn_dropout: float = 0.0, nb_rnnoutdim: int = 1200, rnn_dropout: int = 0.2, final_activation: Literal['softplus', 'softsign', 'relu', 'tanh', 'sigmoid', 'hard_sigmoid', 'linear'] = 'softmax', dense_wl2reg: float = 0.0, dense_bl2reg: float = 0.0, optimizer: Literal['sgd', 'rmsprop', 'adagrad', 'adadelta', 'adam', 'adamax', 'nadam'] = 'adam') tensorflow.keras.models.Model[source]
Create a C-LSTM model for word embeddings.
- Args:
nb_labels: Number of class labels. wvmodel: Word embedding model. If provided, vecsize is extracted from it. nb_filters: Number of CNN filters. Default: 1200. n_gram: N-gram (window size). Default: 2. maxlen: Maximum sentence length. Default: 15. vecsize: Embedding vector size. Default: 300. cnn_dropout: CNN dropout rate. Default: 0.0. nb_rnnoutdim: LSTM output dimension. Default: 1200. rnn_dropout: LSTM dropout rate. Default: 0.2. final_activation: Final layer activation. Default: softmax. dense_wl2reg: L2 regularization for weights. Default: 0.0. dense_bl2reg: L2 regularization for bias. Default: 0.0. optimizer: Optimizer. Default: adam.
- Returns:
Keras Sequential model.
- Reference:
Chunting Zhou et al., “A C-LSTM Neural Network for Text Classification,” arXiv:1511.08630 (2015). https://arxiv.org/abs/1511.08630
ConvNet (Convolutional Neural Network)
This neural network for supervised learning is using convolutional neural network (ConvNet), as demonstrated in Kim’s paper.
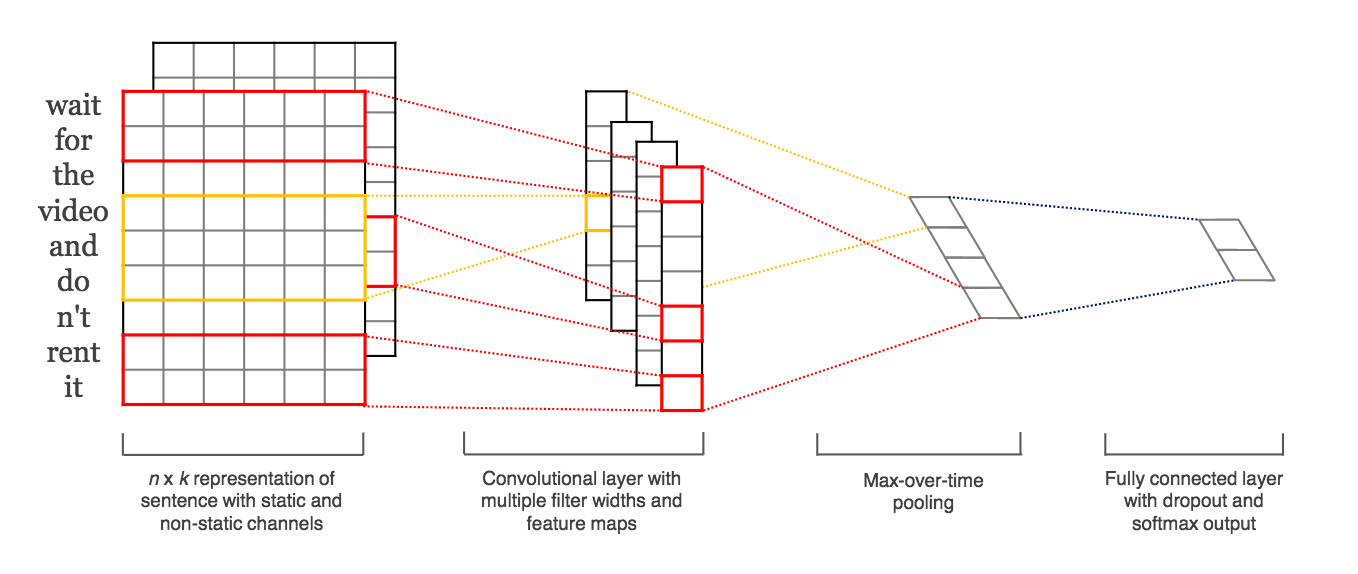
The function in the frameworks returns a keras.models.Sequential or keras.models.Model. Its input parameters are:
The parameter maxlen defines the maximum length of the sentences. If the sentence has less than maxlen words, then the empty words will be filled with zero vectors.
>>> kmodel = fr.CNNWordEmbed(len(trainclassdict.keys()), vecsize=wvmodel.vector_size)
Double ConvNet
This neural network is nothing more than two ConvNet layers. The function in the frameworks returns a keras.models.Sequential or keras.models.Model. Its input parameters are:
The parameter maxlen defines the maximum length of the sentences. If the sentence has less than maxlen words, then the empty words will be filled with zero vectors.
>>> kmodel = fr.DoubleCNNWordEmbed(len(trainclassdict.keys()), vecsize=wvmodel.vector_size)
C-LSTM (Convolutional Long Short-Term Memory)
This neural network for supervised learning is using C-LSTM, according to the paper written by Zhou et. al. It is a neural network with ConvNet as the first layer, and then followed by LSTM (long short-term memory), a type of recurrent neural network (RNN).
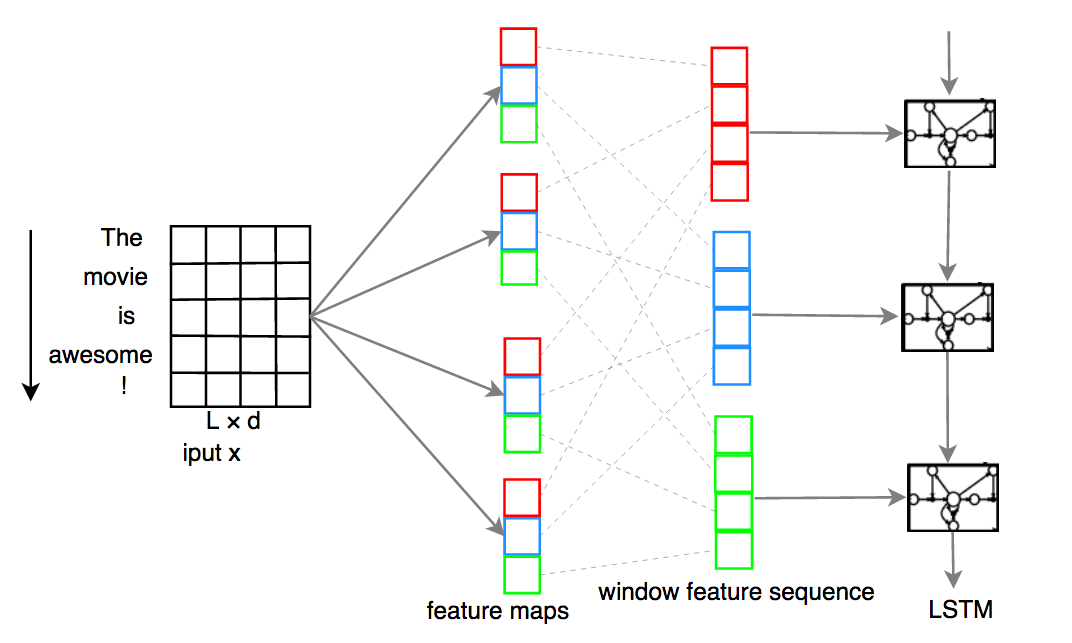
The function in the frameworks returns a keras.models.Sequential or keras.models.Model.
The parameter maxlen defines the maximum length of the sentences. If the sentence has less than maxlen words, then the empty words will be filled with zero vectors.
>>> kmodel = fr.CLSTMWordEmbed(len(trainclassdict.keys()), vecsize=wvmodel.vector_size)
User-Defined Neural Network
Users can define their own neural network for use in the classifier wrapped by
shorttext.classifiers.VarNNEmbeddedVecClassifier
as long as the following criteria are met:
the input matrix is
numpy.ndarray, and of shape (maxlen, vecsize), where
maxlen is the maximum length of the sentence, and vecsize is the number of dimensions of the embedded vectors. The output is a one-dimensional array, of size equal to the number of classes provided by the training data. The order of the class labels is assumed to be the same as the order of the given training data (stored as a Python dictionary).
Putting Word2Vec Model As an Input Keras Layer (Deprecated)
This functionality is removed since release 0.5.11, due to the following reasons:
keras changed its code that produces this bug;
the layer is consuming memory;
only Word2Vec is supported; and
the results are incorrect.
Reference
Chunting Zhou, Chonglin Sun, Zhiyuan Liu, Francis Lau, “A C-LSTM Neural Network for Text Classification,” (arXiv:1511.08630). [arXiv]
“CS231n Convolutional Neural Networks for Visual Recognition,” Stanford Online Course. [link]
Nal Kalchbrenner, Edward Grefenstette, Phil Blunsom, “A Convolutional Neural Network for Modelling Sentences,” Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, pp. 655-665 (2014). [arXiv]
Tal Perry, “Convolutional Methods for Text,” Medium (2017). [Medium]
Yoon Kim, “Convolutional Neural Networks for Sentence Classification,” EMNLP 2014, 1746-1751 (arXiv:1408.5882). [arXiv]
Zackary C. Lipton, John Berkowitz, “A Critical Review of Recurrent Neural Networks for Sequence Learning,” arXiv:1506.00019 (2015). [arXiv]
Home: Homepage of shorttext